
by Tübingen AI Center / Elia Schmid
Celestine Mendler-Dünner
I am a Principal Investigator at the ELLIS Institute Tübingen, co-affiliated with the Max Planck Institute for Intelligent Systems and the Tübingen AI Center. My research develops foundations of AI with a focus on the interaction between learning algorithms and society. Topics of interest include performative prediction, algorithmic collective action, and the use of LLMs for risk scoring and social simulation. At the ELLIS Institute I lead the Algorithms and Society group. Before, I was a researcher at the Max Planck Institute for Intelligent Systems and spent two years as a SNSF postdoctoral fellow at UC Berkeley. I obtained my PhD from ETH Zurich, in collaboration with IBM Research Zurich where I co-lead the design of the IBM Snap ML library. I am an ELLIS Scholar and I serve as member of the Board of Directors for EAAMO and the associated ACM EAAMO conference.
Highlights
-
06/2026
Speaking at the Hi!Paris Summer School about performativity
-
12/2025
Workshop on Algorithmic Collective Action at NeurIPS (website)
-
09/2025
Speaking at the Swiss CLOCK Summit in Engelberg
-
06/2025
Snap ML reached 1 million downloads on pypi!
-
04/2025
"Performative Prediction: Past and Future'' accepted to Statistical Science
-
12/2024
NeurIPS oral -- join us for Ricardo's talk on LLMs and surveys in Vancouver
-
12/2024
Speaking at the MPG AI & Research event in Berlin
-
11/2024
Speaking at the ETH Seminar on Law & Economics and the ML meets Law Workshop in Tübingen
-
09/2024
Keynote talk at the Cornell Thought Summit on the Future of Survey Science
-
07/2024
Invited tutorial on Performative Prediction at UAI with Tijana
-
06/2024
Speaking at the ELLIS Institute Opening
-
12/2023
Invited talk at the NeurIPS Workshop on Algorithmic Fairness
-
11/2023
Serving as Program Chair for EAAMO'23
-
05/2023
Speaking at the Oxford Workshop for Social Foundations of Statistics and ML
-
02/2023
Speaking at the TILOS-OPTML++ Seminar at MIT
Featured Research Projects
My research broadly studies foundations of machine learning with a focus on social questions. Together with my group I am working towards developing theoretical as well as practical tools to support safe, reliable and trustworthy machine learning with a positive impact on society. Below you can find our main research themes:LLMs and Surveys
As large language models increase in capability, researchers have started to conduct surveys of all kinds on these models---research questions rage from learning about biases and alignment of LLMs, to extracting information about human subpopulations and using them as a data source for social science research. In our work we critically examine the validity of surveys as a method to extract population statistics from LLMs. We explain pitfalls, develop tools for the systematic testing of the capabilities of LLMs to emulate human outcomes, and explore the use of survey data for evaluating and fine-tuning LLMs.
Links and Resources
- Questioning the survey responses of LLMs: NeurIPS 2024 oral
- Folktexts: a Python library to becnhmark LLMs ability to predict human outcomes againt survey data.
Performative Prediction
Predictions when deployed in societal systems can trigger actions and reactions of individuals. Thereby they can change the way the broader system behaves -- a dynamic effect that traditional machine learning fails to account for. To formalize and reason about performativity in the context of machine learning, we have developed the framework of performative prediction. It extends the classical risk minimization framework and allows the data distribution to depend on the deployed model. This inherently dynamic viewpoint brings forth interesting connections to concepts from causality, game theory and control, and it leads to new solution concepts, optimization challenges, and fundamental questions about the goals of prediction in social context.
Links and Resources
- Performative Prediction. ICML 2020.
- Survey paper. Statistical Science 2025.
- Tutorial. UAI 2024.
Power in Digital Economies
Algorithmic predictions play an increasingly important role in digital economies as they mediate services, platforms, and markets at societal scale. The fact that such services can steer the behavior of consumers is a central concern in many policy questions. We are exploring how the concept of performativity can help quantify economic power and support digital market investigations. Intuitively, the more powerful a firm has, the more performative their predictions, a causal effect strength we can measure from observational and experimental data.
Links and Resources
- Performative Power NeurIPS 2022.
- An online experiment to measure performative power of online search: https://powermeter.is.tue.mpg.de/
Algorithmic Collective Action
How can participants steer AI systems toward a common good? We explore data as a lever for participants to impact learning outcomes from below. Research questions encompass the design of goals and strategies, their effectiveness in different learning settings, challenges of coordination, as well as connection to labor markets, power dynamics, and collective action in political economy.
Links and Resources
- Theoretical framework. ICML 2022.
- NeurIPS'25 workshop on Algorithmic Collective Action.
- A Github collection of documented cases in the gig economy
- An application to music recommendation. NeurIPS 2024.
Scalable Learning Algorithms
When building societal-scale machine learning systems, training time and resource constraints can be a critical bottleneck for dynamic system optimization. Efficient training algorithms that are aware of distributed architectures, interconnect topologies, memory constraints and accelerator units form an important bilding block towards using available resources most efficiently. As part of my PhD research, we demonstrated that system-aware algroithms can lead to several orders of magnitude reduction in training time compared to standard system-agnostic methods. Today, the innovations of my PhD work form the backbone of the IBM Snap ML library that has been integrated with several of IBM's core AI products.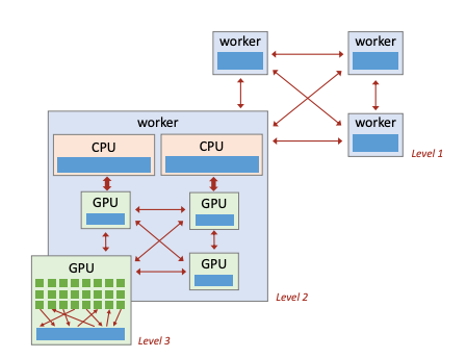
Links and Resources
- IBM Snap ML Library (>1M downloads on pypi)
- Paper describing Snap ML architecture: NeurIPS 2018
- Dissertation on System-Aware Algorithms for ML
Affiliations and Awards
I am an ELLIS Scholar, a core faculty member of the Tübingen AI Center and the International Max Planck Research School for Intelligent Systems (IMPRS-IS), and an associated faculty member at the Max Planck ETH Center for Learning Systems (CLS). I am also a member of the Tübingen Cluster of Excellence on ML for Science, and a fellow of the Elisabeth-Schiemann Kolleg of the Max Planck Society. For my dissertation I was awarded the ETH Medal. For the high industrial impact of my research on system-aware algorithm design I received the IBM Research Devision Award, the IBM Eminence and Excellence Award, and the Fritz Kutter Prize. My Postdoc was supported by the SNSF Early Postdoc Mobility Fellowship by the Swiss National Science Foundation.Advising
I have the pleasure of advising and collaborating with excellent students (group website):- PhD Students: Patrik Wolf
- Research Interns: Pedram
Khorsandi, Léo Le Douarec, Coco Koban, Gabe Smithline
- Alumni: Joachim Baumann, Dorothee Sigg, Haiqing Zhu, Anna Badalyan
Resources, Media and Recordings
- Folktexts datasets available on HuggingFace and Github
- UAI tutorial recording: An Introduction to Performative Prediction
- Powermeter is available in the Chrome store
- Montreal AI Ethics Institute blog post on Performative Power.
- Invited talk NeurIPS workshop on Algorithmic Fairness Through the Lense of Time.
- Invited talk Oxford Workshop on Social Foundations of Statistics and Machine Learning
- Invited talk MIT Optimization Seminar
-
Snap ML has been integrated with the AI Toolkit for IBM Z and Watson ML.
-
Snap ML available through PyPi: > pip install snapml (see Medium article)
- General audience interview for the Cyber Valley Podcast Series, see below.

Publications and Preprints
Peer-reviewed Workshop Contributions
Patents
US11803779B2 - T. Parnell, A. Anghel, N. Ioannou, N. Papandreou, C. Mendler-Dünner, D.
Sarigiannis, H. Pozidis.
US11573803B2 - N. Ioannou, C. Dünner, T. Parnell.
US11562270B2 - M. Kaufmann, T. Parnell, A. Kourtis, C. Mendler-Dünner.
US11461694B2 - T. Parnell, C. Dünner, D. Sarigiannis, H. Pozidis.
US11315035B2 - T. Parnell, C. Dünner, H. Pozidis, D. Sarigiannis
US11301776B2 - C. Dünner, T. Parnell, H. Pozidis.
US11295236B2 - C. Dünner, T. Parnell, H. Pozidis.
US10147103B2 - C. Dünner, T. Parnell, H. Pozidis, V. Vasileiadis, M. Vlachos.
US10839255B2 - K. Atasu, C. Dünner, T. Mittelholzer, T. Parnell, H. Pozidis, M. Vlachos.